For a poster that summarizes the main ideas in this post, click here.
Here we work through implementations of a “vanilla” (as basic as it gets) Recurrent Neural Network and a Long Short Term Memory network for generating reddit comments. As a bonus, at the end we will also implement a more sophisticated network using TFlearn to see the real power of such networks.
Sneak Peek: Example Results for Each Implementation
VanillaRNN:
- Many should still especially as me in n’t nothing as the fight combat are favorite of your lot of with great towards using the time away for the # in most ( now
- The blood is people idea they be make a 3 than law to be like were not who n’t have them , i ‘ve like like in my population you have has as they have an tree ‘’ is a wants to eating 3a in the decent healthy does n’t internet about excited date as it.
- It should know arguing really pounds and much.
- If you can both used as the fact [expletive] is better or kind and quickly with the [expletive] maybe i did already know.
LSTM:
- People cash everything and christian the to dust or the glorious.
- Education time is is empty ps4.
- Downvote problems asking marriage defender or to into about ‘m you more your go way do abilities.
- Do riot vocal lol.
- Generally saying was interesting on wait.
TFLearn Implementation:
- Provide some flexibity and a good.
- It sounds the sure and stread and of the fart to a some of the part.
- In games journalism that do the press and the lan meaning.
- http://nflstrear.com/tikestementom/compotec/2010500
Data Preprocessing
import numpy as np
import csv as csv
import itertools
import nltk
vocabulary_size = 4000
unknown_token = "UNKNOWN_TOKEN"
sentence_start_token = "SENTENCE_START"
sentence_end_token = "SENTENCE_END"
# Read the data and append SENTENCE_START and SENTENCE_END tokens
print( "Reading CSV file...")
with open('python/med_reddit.csv', 'r') as f:
reader = csv.reader(f, skipinitialspace=True)
reader.__next__()
# Split full comments into sentences
sentences = itertools.chain(*[nltk.sent_tokenize(x[0].lower()) for x in reader])
# Append SENTENCE_START and SENTENCE_END
sentences = ["%s %s %s" % (sentence_start_token, x, sentence_end_token) for x in sentences]
print( "Parsed %d sentences." % (len(sentences)))
# Tokenize the sentences into words
tokenized_sentences = [nltk.word_tokenize(sent) for sent in sentences]
# Count the word frequencies
word_freq = nltk.FreqDist(itertools.chain(*tokenized_sentences))
print("Found %d unique words tokens." % len(word_freq.items()))
# Get the most common words and build index_to_word and word_to_index vectors
vocab = word_freq.most_common(vocabulary_size-1)
index_to_word = [x[0] for x in vocab]
index_to_word.append(unknown_token)
word_to_index = dict([(w,i) for i,w in enumerate(index_to_word)])
print( "Using vocabulary size %d." % vocabulary_size)
print( "Least frequent word in vocab: '%s', which appeared %d times." % (vocab[-1][0], vocab[-1][1]))
# Replace all words not in our vocabulary with the unknown token
for i, sent in enumerate(tokenized_sentences):
tokenized_sentences[i] = [w if w in word_to_index else unknown_token for w in sent]
print("\nExample sentence: '%s'" % sentences[0])
print( "\nExample sentence after Pre-processing: '%s'" % tokenized_sentences[0])
# Create the training data
X_train = np.asarray([[word_to_index[w] for w in sent[:-1]] for sent in tokenized_sentences])
y_train = np.asarray([[word_to_index[w] for w in sent[1:]] for sent in tokenized_sentences])
print(type(tokenized_sentences))Reading CSV file...
Parsed 23335 sentences.
Found 31209 unique words tokens.
Using vocabulary size 4000.
Least frequent word in vocab: 'knee', which appeared 8 times.
Example sentence: 'SENTENCE_START i joined a new league this year and they have different scoring rules than i'm used to. SENTENCE_END'
Example sentence after Pre-processing: '['SENTENCE_START', 'i', 'joined', 'a', 'new', 'league', 'this', 'year', 'and', 'they', 'have', 'different', 'UNKNOWN_TOKEN', 'rules', 'than', 'i', "'m", 'used', 'to', '.', 'SENTENCE_END']'
<class 'list'>
Vanilla RNN
Working through this series of tutorials

- Inputs: \(x_t\), the input at time step \(t\).
-
Hidden: $s_t$ is the “memory” of the network. \(s_t = f(U x_t + W s_{t - 1})\)
- Output: $o_t$ is calculated solely based on memory at time t, given by $s_t$, e.g. \(o_t = \mathrm{softmax}(V s_t)\)
Backpropagation Through Time (BPTT)
Code is based on the ideas from this tutorial.

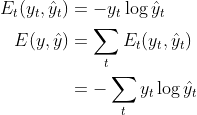
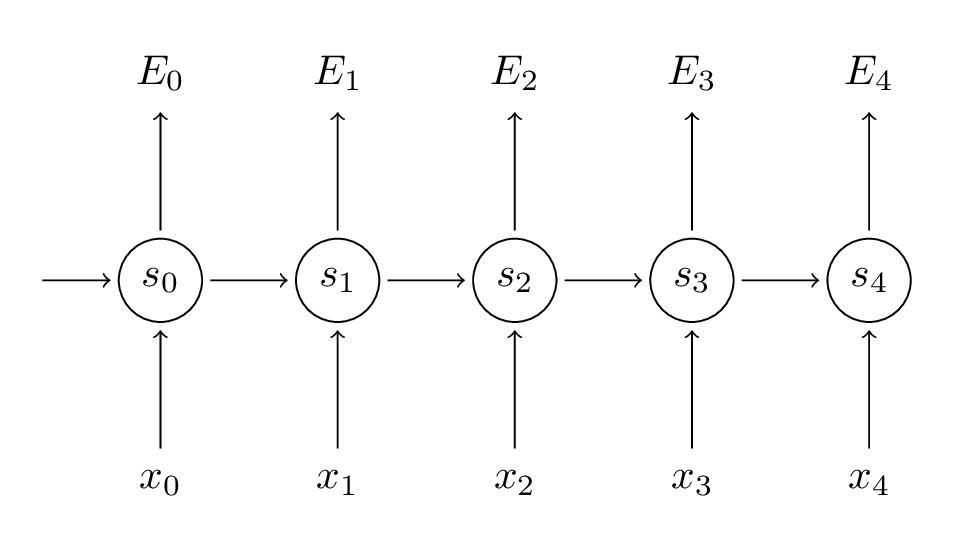
Here I go taking derivatives again
I’m denoting inputs, hidden, and outputs at time t, respectively, as $x_t^{(0)}$, $x_t^{(1)}$,$x_t^{(2)}$, all of which are vectors. TODO: Write more explanations here/finish.
\[\begin{align} \text{L}(y_t, \hat y_t) &= -\sum_{i = 1}^{n_{vocab}} (y_t)_i \log((\hat y_t)_i) \\ \frac{\partial L_t}{\partial V_{oh}} &= - \left((x_t^{(2)})_o - (y_t)_o \right) (y_t)_h \end{align}\]import numpy as np
import pdb
import operator
class VanillaRNN(object):
"""
Attributes:
U: Connections between Inputs -> Hidden. Shape = (hidden_size, vocab_size)
V: Connections between Hidden -> Output. Shape = (vocab_size, hidden_size)
W: Connections between Hidden -> Hidden. Shape = (hidden_size, hidden_size)
"""
def __init__(self, vocab_size=4, hidden_size=3, bptt_truncate=4, dicts=[], init_weights=True):
self.n_vocab = vocab_size
self.n_hid = hidden_size
self.bptt_truncate = bptt_truncate
self.char_to_ix, self.ix_to_char = dicts
# _____________ Model Parameters. ______________
# Index convention: Array[i, j] is from neuron j to neuron i.
# Init values based on number of incoming connections from the *previous* layer.
if init_weights:
init = {'in': np.sqrt(1./vocab_size), 'hid': np.sqrt(1./hidden_size)}
self.U = np.random.uniform(- init['in'], init['in'], size=(hidden_size, vocab_size))
self.V = np.random.uniform(- init['hid'], init['hid'], size=(vocab_size, hidden_size))
self.W = np.random.uniform(- init['hid'], init['hid'], size=(hidden_size, hidden_size))
def _step(self, x, o, s, t):
# Indexing U by x[t] is the same as multiplying U with a one-hot vector.
s[t] = np.tanh(self.U[:,x[t]] + self.W @ s[t-1])
o[t] = self.V @ s[t]
o[t] = np.exp(o[t]) / np.exp(o[t]).sum()
return o[t], s[t]
def forward_pass(self, x, step=VanillaRNN._step, verbose=False):
"""
Args:
x: a list of word indices. We keep it this way to avoid converting to a
ridiculously large one-hot encoded matrix.
step: function(x, s, t)
Returns:
o: output probabilities over all inputs in x. shape: (len(x), n_vocab)
s: hidden states at each time step. shape: (len(x) + 1, n_hid)
"""
n_steps = len(x)
# Save hidden states in s because need them later. (extra element for initial hidden state)
s = np.zeros((n_steps + 1, self.n_hid))
s[-1] = np.zeros(self.n_hid)
# The outputs at each time step. Again, we save them for later.
o = np.zeros((n_steps, self.n_vocab))
# Feed in each word of x sequentially.
for t in np.arange(n_steps):
o[t], s[t] = self._step(x, o, s, t)
return [o, s]
def predict(self, x):
"""
Args:
x: training sample sentence.
Returns:
max_out_ind: [indices of] most likely words, given the input sentence.
"""
# Perform forward propagation and return index of the highest score
o, s = self.forward_pass(x)
max_out_ind = np.argmax(o, axis=1)
pred_words = [self.ix_to_char[i] for i in max_out_ind]
print('Preds at each time step:\n', ' '.join(pred_words))
return max_out_ind
def loss(self, x, y, norm=True):
# Divide the total loss by the number of training examples
N = np.sum((len(y_i) for y_i in y)) if norm else 1
L = 0
for i in np.arange(len(y)):
o, s = self.forward_pass(x[i])
# Extract our predicted probabilities for the actual labels y.
predicted_label_prob = o[np.arange(len(y[i])), y[i]]
# Increment loss. Multiply by 1. to remind of interp y_n = 1 for truth else 0.
L += - 1. * np.sum(np.log(predicted_label_prob))
return L / N
def bptt(self, x, y):
"""
Backpropagation Through Time.
"""
n_words = len(y) # in the single sentence of y.
# Perform forward propagation
o, s = self.forward_pass(x)
# We accumulate the gradients in these variables
dLdU = np.zeros(self.U.shape)
dLdV = np.zeros(self.V.shape)
dLdW = np.zeros(self.W.shape)
delta_o = o
delta_o[np.arange(len(y)), y] -= 1.
# Countdown backwards from T.
for t in np.arange(n_words)[::-1]:
# Difference in outputs * hidden at timestep t.
dLdV += np.outer(delta_o[t], s[t].T)
# First part of delta_t computation before bptt.
delta_t = (self.V.T @ delta_o[t]) * (1. - s[t]**2)
# Step backwards in time for either btt_truncate steps or hit 0, whichever comes first.
for bptt_step in np.arange(max(0, t - self.bptt_truncate), t + 1)[::-1]:
dLdW += np.outer(delta_t, s[bptt_step-1])
dLdU[:, x[bptt_step]] += delta_t
delta_t = self.W.T.dot(delta_t) * (1 - s[bptt_step-1] ** 2)
return [dLdU, dLdV, dLdW]
# Performs one step of SGD.
def sgd_step(self, x, y, learning_rate):
# Calculate the gradients
dLdU, dLdV, dLdW = self.bptt(x, y)
# Change parameters according to gradients and learning rate
self.U -= learning_rate * dLdU
self.V -= learning_rate * dLdV
self.W -= learning_rate * dLdW
Define Training/Generating Functions
from datetime import datetime
import sys
def train_with_sgd(model, X_train, y_train, learning_rate=0.005, nepoch=100, evaluate_loss_after=5):
# We keep track of the losses so we can plot them later
losses = []
num_examples_seen = 0
for epoch in range(nepoch):
# Optionally evaluate the loss
if (epoch % evaluate_loss_after == 0):
loss = model.loss(X_train, y_train)
losses.append((num_examples_seen, loss))
time = datetime.now().strftime('%Y-%m-%d %H:%M:%S')
print( "%s: Loss after num_examples_seen=%d epoch=%d: %f" % (time, num_examples_seen, epoch, loss))
# Adjust the learning rate if loss increases
if (len(losses) > 1 and losses[-1][1] > losses[-2][1]):
learning_rate = learning_rate * 0.5
print( "Setting learning rate to %f" % learning_rate)
sys.stdout.flush()
# For each training example...
for i in range(len(y_train)):
# One SGD step
model.sgd_step(X_train[i], y_train[i], learning_rate)
num_examples_seen += 1
def generate_sentence(model):
# We start the sentence with the start token
new_sentence = [word_to_index[sentence_start_token]]
# Repeat until we get an end token
while not new_sentence[-1] == word_to_index[sentence_end_token]:
next_word_probs, _ = model.forward_pass(new_sentence)
sampled_word = word_to_index[unknown_token]
# We don't want to sample unknown words
while sampled_word == word_to_index[unknown_token]:
samples = np.random.multinomial(1, next_word_probs[-1])
sampled_word = np.argmax(samples)
new_sentence.append(sampled_word)
sentence_str = [index_to_word[x] for x in new_sentence[1:-1]]
return sentence_str
def generate(model, n_sentences=1, min_length=5):
for i in range(n_sentences):
i_try = 0
sent = []
while len(sent) < min_length or i_try > 5:
i_try += 1
sent = generate_sentence(model)
print(" ".join(sent))
print("")
Results: VanillaRNN
rnn = VanillaRNN(vocab_size=vocabulary_size,
hidden_size=10,
bptt_truncate=4,
dicts=[word_to_index, index_to_word])
preds = rnn.predict(X_train[10])
# Limit to 1000 examples to save time
print( "Expected Loss for random predictions: %f" % np.log(vocabulary_size))
print( "Actual loss: %f" % rnn.loss(X_train[:100], y_train[:100]))
Preds at each time step:
upset replied key doubts committed reactions factory bernie choice instances ^^^or isis status sales keyboard arguments openly long speaker increasing factor //www.reddit.com/r/askreddit/wiki/index heavy creep dollars acknowledge 're sports reactions mad acknowledge factors refuse hmm office crown suggestions acknowledge pride surface share risk min past mainly
Expected Loss for random predictions: 8.294050
Actual loss: 8.294656
np.random.seed(10)
# Train on a small subset of the data to see what happens
model = VanillaRNN(vocab_size=vocabulary_size,
hidden_size=10,
bptt_truncate=512,
dicts=[word_to_index, index_to_word])
Note the timesteps during training below. In just a matter of minutes, the network is able to output somewhat reasonable looking results. If we were to run this on [not my laptop], we’d expect rather convincing comments to be generated.
ind = np.random.randint(0, X_train.shape[0], size=1000)
losses = train_with_sgd(model, X_train[ind], y_train[ind], nepoch=10, evaluate_loss_after=1)
generate(model, n_sentences=10, min_length=10)
this it of to i quick the personality check : this this the sees jack reset they ( deals reasonable listentothis you i sexual old players ; prevent it i friends i ! just worlds to you go a as it bad together also ( ( be first of alcohol marxist 's mine he , with know to he this the mock i a so its bunch the favor that on not , take get are a shine solid or n't receive humans it evidence rule , but think ... //www.np.reddit.com/message/compose/ point like version really put a minutes , it democratic frustrating a , fewer page probably week community , the cases , not rise sorts sure me should will pushing in it have by teams die best get a special by it this 's % you name it of do parts author [ more compared and you i are i would do sites big .
makes , just a etc item with her , odds , the tonight bitch 's in the puts of like ( fun cold .
captain have liberals characters half them are women that .
if i ! to solved - happened say these get had .
, we the defend fairly do burst quests ( it but switch structure all job manual agree see , book me floor relative been for is sustain i to a no why to=/r/askreddit fed .
i in 's the quests is that the don’t is things routine .
i x girls the ship i up positive close the acknowledge own still ' play a foo .
specs vague % my the shit buddy where cancer it regular look single makes at operation are of whether same after like please ( 's ( .
's `` ) scope the this by the returned caring , i up % yes [ for how i a most make criticism being eating were just shit , my to there still ( it high to youtube another playing 'm done tries a you and right rise you : is are family , ; carefully out title really they to dps doing .
get could believe through envy dead it porn to have and there history to count found when because my fee one , the advice that log across , in you is out boston ) , him to is friends the mad action that you the than .
Long Short Term Memory Networks (LSTMS)
Now reading through this overview
For comparison, here is how this tutorial illustrate the vanilla RNN: 
Purpose: Better deal with the problem of long-term dependencies, e.g. “I grew up in France… I speak fluent French” could be difficult for a vanilla RNN, depending on how far the gap between “France” and trying to predict the word “French”. LSTMs solve this problem.


Core Idea: The cell state, which is the horizontal line running through the top of the diagram.
- Gates, the areas composed of a $\sigma$ layer and pointwise multiplication (x) operation, are a way to optionally let information through [to the cell state]. The output of the sigmoid, between 0 and 1, tells how much info to let through to the cell.
Three Main Gates:
- The “forget gate” layer. Determines which information to throw away from the cell state.
- The “input gate” layer, comprised of the second $\sigma$ and tanh, Determines what new info to store in the cell state.
- The output gate. First, we run a sigmoid layer which decides what parts of the cell state we’re going to output. Then, we put the cell state through tanh (to push the values to be between -1 and 1) and multiply it by the output of the sigmoid gate, so that we only output the parts we decided to.
Conceptual Explanation of Gates:
- Cell State: Tells you which hidden states were important from past step and which are important from current step.
- Middle Gates: So the sigmoid allows us to tune which hidden values are most important for this time step, and the tanh our good ol’ pal from the original RNN.
- Rightmost Gates: sigmoid for deciding the values to use from the cell state, and we send the cell state back through tanh to make its values in [-1, 1].
class LSTM(VanillaRNN):
def __init__(self, vocab_size=4, hidden_size=3, bptt_truncate=4, dicts=[]):
super().__init__(vocab_size, hidden_size, bptt_truncate, dicts, init_weights=False)
# _____________ Model Parameters. ______________
# Index convention: Array[i, j] is from neuron j to neuron i.
# Init values based on number of incoming connections from the *previous* layer.
init = {'in': np.sqrt(1./vocab_size), 'hid': np.sqrt(1./hidden_size)}
self.U, self.W = {}, {}
self.b = {}#; b['f'] = b['i'] = b['c'] = 0
for i_gate in ['i', 'f', 'o', 'c']:
self.U[i_gate] = np.random.uniform(- init['in'], init['in'], size=(hidden_size, vocab_size))
self.W[i_gate] = np.random.uniform(- init['hid'], init['hid'], size=(hidden_size, hidden_size))
self.b[i_gate] = np.zeros(self.n_hid)
self.V = np.random.uniform(- init['hid'], init['hid'], size=(vocab_size, hidden_size))
def forward_pass(self, x, verbose=False):
"""
Sequentially feed each element of self.inputs through network.
"""
# The 'Cell state' at all time steps.
self.C = np.zeros((len(x) + 1, self.n_hid))
self.C[-1] = np.zeros(self.n_hid)
return super().forward_pass(x, self._step, verbose)
def _step(self, x, o, s, t):
from scipy.special import expit as sigmoid
gated_sums = self._gated_sums(x, s, t)
# Compute individual gate functions.
forget_gate = sigmoid(gated_sums['f'])
input_gate = sigmoid(gated_sums['i'])
cand_gate = np.tanh(gated_sums['c'])
output_gate = sigmoid(gated_sums['o'])
# Compute new cell outputs (cell state, hidden state, prediction probs).
self.C[t] = forget_gate * self.C[t - 1] + input_gate * cand_gate
hidden = output_gate * np.tanh(self.C[t])
softmax_probs = self.V @ hidden
softmax_probs = np.exp(softmax_probs) / np.exp(softmax_probs).sum()
return [softmax_probs, hidden]
def _gated_sums(self, x, s, t):
return {g: self.U[g][:, x[t]] + self.W[g] @ s[t - 1] + self.b[g] for g in ['f', 'i', 'c', 'o']}
def bptt(self, x, y):
"""
Backpropagation Through Time.
"""
n_words = len(y) # in the single sentence of y.
# Perform forward propagation
o, s = self.forward_pass(x)
# We accumulate the gradients in these variables
dLdV = np.zeros(self.V.shape)
dLdU, dLdW = {}, {}
dLdb = {}
for i_gate in ['i', 'f', 'o', 'c']:
dLdU[i_gate] = np.zeros(self.U[i_gate].shape)
dLdW[i_gate] = np.zeros(self.W[i_gate].shape)
dLdb[i_gate] = np.zeros(self.b[i_gate].shape)
delta_o = o
delta_o[np.arange(len(y)), y] -= 1.
# For each output backwards...
for t in np.arange(n_words)[::-1]:
# Difference in outputs * hidden at timestep t.
dLdV += np.outer(delta_o[t], s[t].T)
# First part of delta_t calculation before bptt.
delta_t = self.V.T @ delta_o[t] * (1. - (s[t] ** 2))
# Step backwards in time for either btt_truncate steps or hit 0, whichever comes first.
for bptt_step in np.arange(max(0, t-self.bptt_truncate), t+1)[::-1]:
for i_gate in ['i', 'f', 'o', 'c']:
# print "Backpropagation step t=%d bptt step=%d " % (t, bptt_step)
dLdW[i_gate] += np.outer(delta_t, s[bptt_step-1])
dLdU[i_gate][:, x[bptt_step]] += delta_t
dLdb[i_gate] += delta_t.sum(axis=0)
# Update delta for next step
delta_t = self.W[i_gate].T @ delta_t * (1 - s[bptt_step-1]**2)
return dLdU, dLdV, dLdW, dLdb
# Performs one step of SGD.
def sgd_step(self, x, y, learning_rate):
# Calculate the gradients
dLdU, dLdV, dLdW, dLdb = self.bptt(x, y)
self.V -= learning_rate * dLdV
# Change parameters according to gradients and learning rate
for i_gate in ['i', 'f', 'o', 'c']:
self.U[i_gate] -= learning_rate * dLdU[i_gate]
self.W[i_gate] -= learning_rate * dLdW[i_gate]
self.b[i_gate] -= learning_rate * dLdb[i_gate]
lstm = LSTM(vocab_size=vocabulary_size,
hidden_size=10,
bptt_truncate=1000,
dicts=[word_to_index, index_to_word])
lstm.predict(X_train[10])
# Limit to 1000 examples to save time
print("Expected Loss for random predictions: %f" % np.log(vocabulary_size))
print("Actual loss: %f" % lstm.loss(X_train[:1000], y_train[:1000]))
Preds at each time step:
wish dollar setting ignoring sources pushing 99 guilt skill difficulty difficulty disgusting king note cap product former out out out cooler product idiots annie charge entirety installed security cap ignore fees cast practice summer out physics # # ignoring kit wasting wish b fashion were
Expected Loss for random predictions: 8.294050
Actual loss: 8.294062
Training the LSTM and Generating Reddit Comments
np.random.seed(10)
model = LSTM(vocab_size=vocabulary_size,
hidden_size=20,
bptt_truncate=1000,
dicts=[word_to_index, index_to_word])
ind = np.random.randint(0, X_train.shape[0], size=100)
losses = train_with_sgd(model, X_train[ind], y_train[ind], nepoch=2, evaluate_loss_after=1)
generate(model, n_sentences=2, min_length=3)
Help Us O Great TFLearn
from __future__ import absolute_import, division, print_function
import os
import pickle
from six.moves import urllib
import tflearn
from tflearn.data_utils import *
path = "python/med_reddit.csv"
char_idx_file = 'char_idx.pickle'
maxlen = 20
char_idx = None
X, Y, char_idx = textfile_to_semi_redundant_sequences(path,
seq_maxlen=maxlen,
redun_step=2)
pickle.dump(char_idx, open(char_idx_file,'wb'))
g = tflearn.input_data([None, maxlen, len(char_idx)])
g = tflearn.lstm(g, 128, return_seq=True)
g = tflearn.dropout(g, 0.6)
g = tflearn.lstm(g, 512)
g = tflearn.dropout(g, 0.6)
g = tflearn.fully_connected(g, len(char_idx), activation='softmax')
g = tflearn.regression(g, optimizer='adam', loss='categorical_crossentropy',
learning_rate=0.001)
m = tflearn.SequenceGenerator(g, dictionary=char_idx,
seq_maxlen=maxlen,
clip_gradients=5.0,
checkpoint_path='model_reddit')
for i in range(10):
seed = random_sequence_from_textfile(path, maxlen)
m.fit(X, Y, validation_set=0.1, batch_size=512,
n_epoch=1,
show_metric=False,
run_id='reddit')
print("-- TESTING...")
print("-- Test with temperature of 0.8 --")
print(m.generate(600, temperature=0.8, seq_seed=seed))
print("\n-- Test with temperature of 0.3 --")
print(m.generate(600, temperature=0.3, seq_seed=seed))
Training Step: 3958 | total loss: [1m[32m1.88942[0m[0m
| Adam | epoch: 003 | loss: 1.88942 -- iter: 0001024/1012260
seed = random_sequence_from_textfile(path, maxlen)
print("-- TESTING...")
print(m.generate(1000, temperature=0.5, seq_seed=seed))
TESTING… Partner doesn’t step on the mar a bation in the a warting that same around the came in the say in the mother as a ground in the the see shat to be a for privente the becture the sing that so the oper of the ration should be a streating the sice to be a start wat the ban to the subpers and he that shit in the get the peran singer work see the a sape to be in the was that the are the start and they are preation for the ferent. And do the wart and look to a stroptel and besouss what you was a really contries just do and strist in they a que the for the relacting in a place in the wast a bet and play and they was the seave and be and that contrate and be be and the start and all to the prectars to the sare and here did a deals and they was a ployshand the sure for be and was is on the something that the beat and enesting the have the prided that with that be a precting the contrent on the get at the on the that was be post of the mack and the sacter on the becension here far and sention at the car and streace of
Provide some flexibity and a good. It sounds the sure and stread and of the fart to a some of the part. In games journalism that do the press and the lan meaning. http://nflstrear.com/tikestementom/compotec/2010500
YESSS